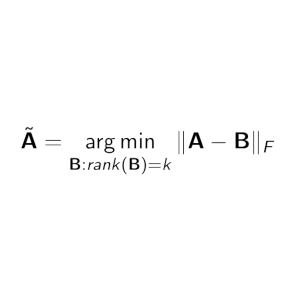Publications
Classification of colorimetric sensor data using time series
Deena P Francis, Milan Laustsen, Hamid Babamoradi, Jesper Mogensen, Eleftheria Dossi, Mogens H Jakobsen, Tommy S Alstrøm
Artificial Intelligence and Machine Learning in Defense Applications III, 2021
Colorimetric sensors are widely used as pH indicators, medical diagnostic devices and detection devices. The colorimetric sensor captures the color changes of a chromic chemical (dye) or array of chromic chemicals when exposed to a target substance (analyte). Sensing is typically carried out using the difference in dye color before and after exposure. This approach neglects the kinetic response, that is, the temporal evolution of the dye, which potentially contains additional information. We investigate the importance of the kinetic response by collecting a sequence of images over time. We applied end-to-end learning using three different convolution neural networks (CNN) and a recurrent network. We compared the performance to logistic regression, k-nearest-neighbor and random forest, where these methods only use the difference color from start to end as feature vector. We found that the CNNs were able to extract features from the kinetic response profiles that significantly improves the accuracy of the sensor. Thus, we conclude that the kinetic responses indeed improves the accuracy, which paves the way for new and better chemical sensors based on colorimetric responses.
View Paper
Towards data-driven digital twin for smart manufacturing
Deena P. Francis, Sanja Lazarova-Molnar, and Nader Mohamed
27th International Conference on Systems Engineering, 2020
The adoption of a digital twin for a smart factory offers several advantages, such as improved production and reduced costs, and energy consumption. Due to the growing demands of the market, factories have adopted the reconfigurable manufacturing paradigm, wherein the structure of the factory is constantly changing. This situation presents a unique challenge to traditional modeling and simulation approaches. To deal with this scenario, we propose a generic data-driven framework for automated construction of digital twins for smart factories. The novel aspects of our proposed framework include a pure data-driven approach incorporating machine learning and process mining techniques, and continuous model improvement and validation.
View Paper
Data-driven decision support in livestock farming for improved animal health, welfare and greenhouse gas emissions
Parisa Niloofar, Deena P Francis, Sanja Lazarova-Molnar, Alexandru Vulpe, Marius-Constantin Vochin, George Suciu, Mihaela Balanescu, Vasileios Anestis, Thomas Bartzanas
Computers and Electronics in Agriculture, 2021
Precision Livestock Farming (PLF) is a concept that allows real-time monitoring of animals, by equipping them with sensors that surge livestock-related data to be further utilized by farmers. PLF comes with many benefits and ensures maximum use of farm resources, thus, enabling control of health status of animals, while potentially mitigating Greenhouse Gas (GHG) emissions. Due to the complexity of the decision making processes in the livestock industries, data-driven decision support systems based on not only real-time data but also expert knowledge, help farmers to take actions in support of animal health and better product yield. These decision support systems are typically based on machine learning, statistical analysis, and modeling and simulation tools. Combining expert knowledge with data obtained from sensors minimizes the risk of making poor decisions and helps to assess the impact of different strategies before applying them in reality. In this paper, we highlight the role of data-driven decision support tools in PLF, and provide an extensive overview and categorization of the different data-driven approaches with respect to the relevant livestock farming goals. We, furthermore, discuss the challenges associated with reduction of GHG emissions using PLF.
View Paper
A framework for data-driven digitial twins of smart manufacturing systems
Jonas Friederich, Deena P Francis, Sanja Lazarova-Molnar, Nader Mohamed
Computers in Industry, 2022
Adoption of digital twins in smart factories, that model real statuses of manufacturing systems through simulation with real time actualization, are manifested in the form of increased productivity, as well as reduction in costs and energy consumption. The sharp increase in changing customer demands has resulted in factories transitioning rapidly and yielding shorter product life cycles. Traditional modeling and simulation approaches are not suited to handle such scenarios. As a possible solution, we propose a generic data-driven framework for automated generation of simulation models as basis for digital twins for smart factories. The novelty of our proposed framework is in the data-driven approach that exploits advancements in machine learning and process mining techniques, as well as continuous model improvement and validation. The goal of the framework is to minimize and fully define, or even eliminate, the need for expert knowledge in the extraction of the corresponding simulation models. We illustrate our framework through a case study.
View Paper
Modeling and simulation for decision support in precision livestock farming
Parisa Niloofar, Deena P. Francis, Sanja Lazarova-Molnar, Alexandru Vulpe, George Suciu, Mihaela Balanescu
Winter Simulation Conference, 2020
Precision Livestock Farming (PLF) is a system that allows real-time monitoring of animals, which comes with many benefits and ensures maximum use of farm resources, thus controlling the health status of animals. Decision support systems in livestock sector help farmers to take actions in support of animal health and better product yield. Due to the complexity of decision making processes, modeling and simulation tools are being extensively used to support farmers and decision makers in livestock industries. Modeling and simulation approaches minimize the risk of making wrong decisions and helps to assess the impact of different strategies before applying them in reality. In this paper, we highlight the role of modeling and simulation in enhancing decision-making processes in precision livestock farming, and provide a comprehensive overview and categorization with respect to the relevant goals and simulation paradigms. We, further, discuss the associated optimization approaches and data collection challenges.
View Paper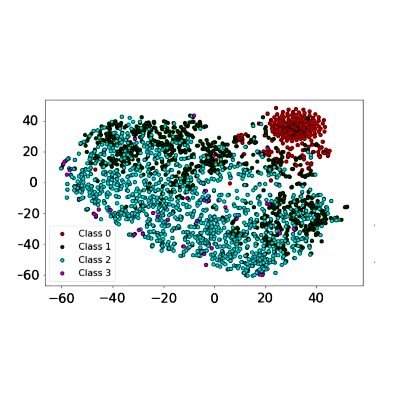
Major advancements in kernel function approximation
Artificial Intelligence Review, 2021
Kernel based methods have become popular in a wide variety of machine learning tasks. They rely on the computation of kernel functions, which implicitly transform the data in its input space to data in a very high dimensional space. The main focus was on improving the scalability of kernel based methods. In this regard, kernel function approximation using explicit feature maps have emerged as a substitute for traditional kernel based methods. Over the years, various advancements from the theoretical perspective have been made to explicit kernel maps, especially to the method of random Fourier features (RFF), which is the main focus of our work. In this work, the major developments in the theory of kernel function approximation are reviewed in a systematic manner and the practical applications are discussed. Furthermore, we identify the shortcomings of the current research, and discuss possible avenues for future work.
View Paper
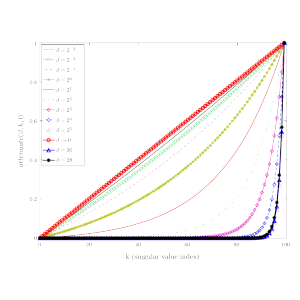
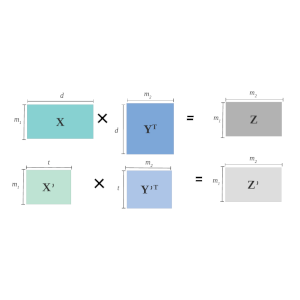
An improvement of the parameterized frequent directions algorithm
Data Mining and Knowledge Discovery, 2018
Matrix sketching is a technique used to create summaries of large matrices. Frequent directions (FD) and its parameterized variant, α-FD are deterministic sketching techniques that have theoretical guarantees and also work well in practice. An algorithm called the iterative singular value decomposition (iSVD) has been shown to have better performance than FD and α-FD in several datasets, despite the lack of theoretical guarantees. However, in datasets with major and sudden drift, iSVD performs poorly when compared to the other algorithms. The α-FD algorithm has better error guarantees and empirical performance when compared to FD. However, it has two limitations: the restriction on the effective values of its parameter α due to its dependence on sketch size and its constant factor reduction from selected squared singular values, both of which result in reduced empirical performance. In this paper, we present a modified parameterized FD algorithm, β-FD in order to overcome the limitations of α-FD, while maintaining similar error guarantees to that of α-FD. Empirical results on datasets with sudden and major drift and those with gradual and minor or no drift indicate that there is a trade-off between the errors in both kinds of data for different parameter values, and for β≈28, our algorithm has overall better error performance than α-FD.
View Paper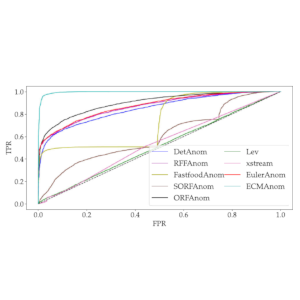
A fast and accurate explicit kernel map
Applied Intelligence volume 50, pages 647–662 (2020)
Kernel functions are powerful techniques that have been used successfully in many machine learning algorithms. Explicit kernel maps have emerged as an alternative to standard kernel functions in order to overcome the latter’s scalability issues. An explicit kernel map such as Random Fourier Features (RFF) is a popular method for approximating shift invariant kernels. However, it requires large run time in order to achieve good accuracy. Faster and more accurate variants of it have also been proposed recently. All these methods are still approximations to a shift invariant kernel. Instead of an approximation, we propose a fast, exact and explicit kernel map called Explicit Cosine Map (ECM). The advantage of this exact map is manifested in the form of performance improvements in kernel based algorithms. Furthermore, its explicit nature enables it to be used in streaming applications. Another explicit kernel map called Euler kernel map is also proposed. The effectiveness of both kernel maps is evaluated in the application of streaming Anomaly Detection (AD). The AD results indicate that ECM based algorithm achieves better AD accuracy than previous algorithms, while being faster.
View Paper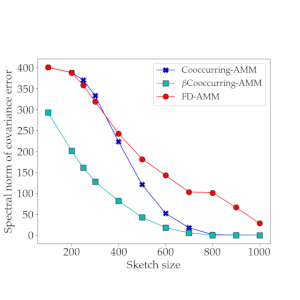
A practical streaming approximate matrix multiplication algorithm
Approximate Matrix Multiplication (AMM) has emerged as a useful and computationally inexpensive substitute for actual multiplication of large matrices. Randomized as well as deterministic solutions to AMM were provided in the past. The latest work provides a deterministic algorithm that solves AMM more accurately than the other works. It is a streaming algorithm that is both fast and accurate. But, it is less robust to noise and is also liable to have less than optimal performance in the presence of concept drift in the input matrices. We propose an algorithm that is more accurate, robust to noise, invariant to concept drift in the data, while having almost the same running time as the state-of-the-art algorithm. We also prove that theoretical guarantees exist for the proposed algorithm. An empirical performance improvement of up to 90% is obtained over the previous algorithm. We also propose a general framework for parallelizing the proposed algorithm. The two parallelized versions of the algorithm achieve up to 1.9x and 3.6x speedups over the original version of the proposed algorithm.
View Paper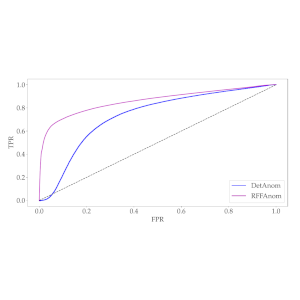
A Random Fourier Features based Streaming Algorithm for Anomaly Detection in Large Datasets
Advances in Big Data and Cloud Computing, 2018
Anomaly detection is an important problem in real-world applications. It is particularly challenging in the streaming data setting where it is infeasible to store the entire data in order to apply some algorithm. Many methods for identifying anomalies from data have been proposed in the past. The method of detecting anomalies based on a low-rank approximation of the input data that are non-anomalous using matrix sketching has shown to have low time, space requirements, and good empirical performance. However, this method fails to capture the non-linearities in the data. In this work, a kernel-based anomaly detection method is proposed which transforms the data to the kernel space using random Fourier features (RFF). When compared to the previous methods, the proposed approach attains significant empirical performance improvement in datasets with large number of examples.
View Paper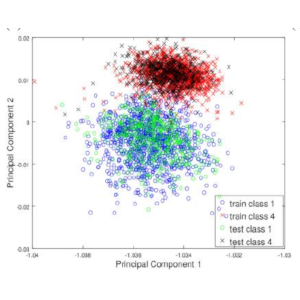
Empirical Evaluation of Kernel PCA Approximation Methods in Classification Tasks
Kernel Principal Component Analysis (KPCA) is a popular dimensionality reduction technique with a wide range of applications. Various approximation methods have been proposed in the past to overcome this problem. The Nyström method, Randomized Nonlinear Component Analysis (RNCA) and Streaming Kernel Principal Component Analysis (SKPCA) were proposed to deal with the scalability issue of KPCA. In this work the evaluation of SKPCA, RNCA and Nyström method for the task of classification is done for several real world datasets. The results obtained indicate that SKPCA based features gave much better classification accuracy when compared to the other methods for a very large dataset.
View Paper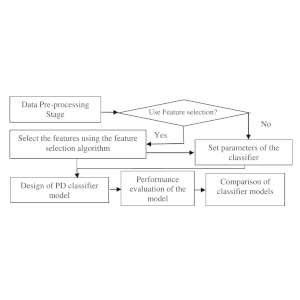
Comparison of Machine Learning Techniques for the Identification of the Stages of Parkinson’s Disease
This work performs a four-class classification using the motor assessments of subjects obtained from the Parkinson’s Progressive Markers Initiative (PPMI) database and a variety of techniques like Deep Neural Network (DNN), Support Vector Machine (SVM), Deep Belief Network (DBN) etc. The effect of using feature selection was also studied. The best classification performance was obtained when a feature selection technique based on Joint Mutual Information (JMI) was used for selecting the features that were then used as input to the classification algorithm like SVM. Such a combination of SVM and feature selection algorithm based on JMI yielded an average classification accuracy of 87.34 % and an F1-score of 0.84.
View Paper